R语言dataframe数据去重
在实习的时候遇到这样的情况:数据集在前期处理过后出现重复的行或者列(例如截短barcode以后导致有重复的列名),从而导致后续数据处理以及训练模型的时候出现错误。此时我们需要对数据进行去重操作。
问题例子
例如,下面的数据集就存在重复的问题(此处使用fread读入):
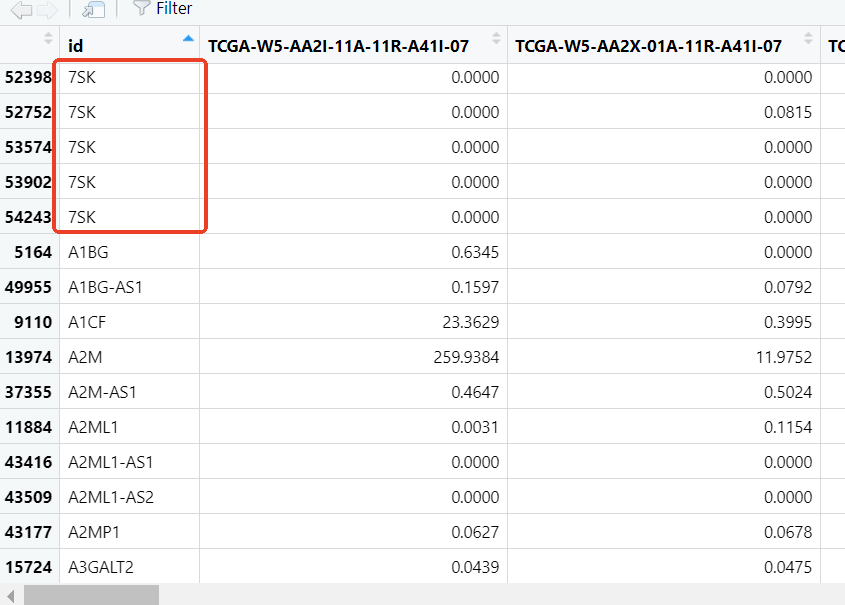
对于这种数据,我们如果在读取时使用id作为行名就会造成错误:

解决方法
下面是我的解决方法:
我们一般采取取平均值的处理方法。即:对于存在重复的基因,我们合并这个基因所有重复的行,并在合并时针对每一个样本取平均值。这是我的代码:
library(data.table)
exp_matrix <- fread("./sampleExp.txt",sep='\t',header=T,check.names=F, skip=1) # 读取文件,注意按照需求修改文件名,是否跳过行之类的。fread读取速度较快
s=Sys.time()
library(limma)
library(stringr)
library(dplyr)
# 有重复则取均值
# 按照'id'列分组,计算每一列的平均值,如有需要请修改
exp_matrix_avg <- exp_matrix %>%
group_by(id) %>%
summarise(across(everything(), mean, na.rm = TRUE))
expr_mean = as.data.frame(exp_matrix_avg)
rownames(expr_mean) = expr_mean[,1]
expr_mean = expr_mean[, -1]
expr_mean <- as.data.frame(t(expr_mean))
e=Sys.time()
print("运行时间:")
print(e-s)
# 此处expr_mean就是处理好的数据集。您可以直接write.table输出保存或者给到其他后续处理步骤之类的我添加了时间统计来评估这个代码的性能。我还制作了好几种其他的版本,这个版本是目前效率最高的。
如果遇到列名需要截断以后导致行名和列名都有重复的情况,就先给行名去重,然后把矩阵转置以后再给新的行名(也就是原来的列名)再去重一遍就行。操作结束后不要忘记再转置回来(如果有需要保留原有格式)。